
Standard natural language processing (NLP) pipelines operate on symbolic representations of language, which typically consist of sequences of discrete tokens. However, creating an analogous representation for ancient logographic writing systems is an extremely labor intensive process that requires expert knowledge. At present, a large portion of logographic data persists in a purely visual form due to the absence of transcription - this issue poses a bottleneck for researchers seeking to apply NLP toolkits to study ancient logographic languages: most of the relevant data are images of writing.
This paper investigates whether direct processing of visual representations of language offers a potential solution. We introduce LogogramNLP, the first benchmark enabling NLP analysis of ancient logographic languages, featuring both transcribed and visual datasets for four writing systems along with annotations for tasks like classification, translation, and parsing. Our experiments compare systems that employ recent visual and text encoding strategies as backbones. The results demonstrate that visual representations outperform textual representations for some investigated tasks, suggesting that visual processing pipelines may unlock a large amount of cultural heritage data of logographic languages for NLP-based analyses.
Almost all early stage languages are logographic, therefore, to better understand how to model the very old languages, languages in glogrpahic writing systems are of best interest.
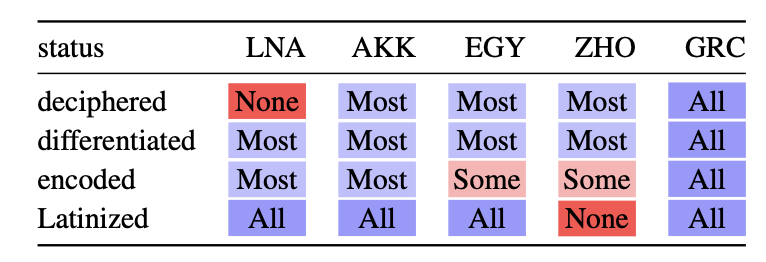
A logographic language uses symbols (logograms) to represent words or morphemes, rather than individual sounds or phonemes as in alphabetic systems. Most ancient languages are not pure alphabetic. In this work, we present a benchmark for four representitive languages in four writing systems: Linear A, Akkadian (Cuneiform), Ancient Egyptian (Hieroglyph), and Old Chinese (Bamboo script).The languages we are interested are older than Ancient Greek or Classical Chinese (文言文). These ancient languages are not fully encoded, differentiated, or not even deciphered. The languages were written on stone tablets, clay pots, and later captured as images.
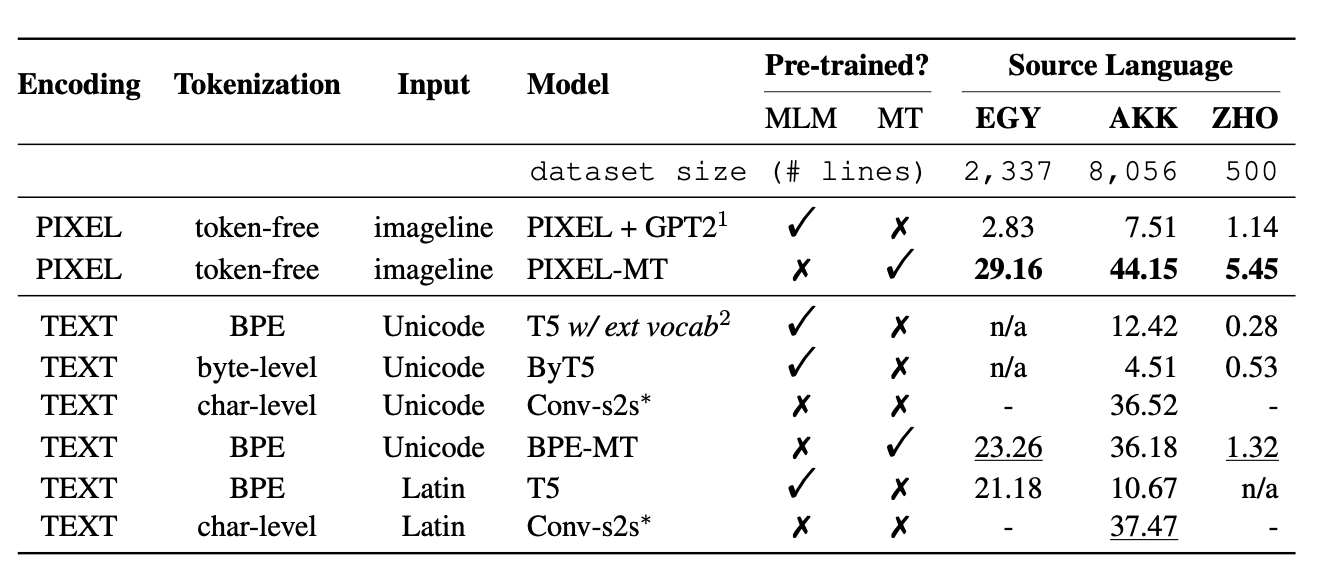
Further, even when text does available, the nature of logoraphic langauges make commonly used low-resouce transfer learning not applicable.

@article{chen2024logogramNLP,
author = {Danlu Chen, Freda Shi, Aditi Agarwal, Jacobo Myerston, Taylor Berg-Krikpatrick},
title = {LogogramNLP: Comparing Visual and Textual Representations of Ancient Logographic Writing Systems for NLP},
journal = {ACL},
year = {2024},
}